Publications
Collection of Research Publications
2026
- Marcus J. Min, Mike He, Zhaoyu Li, Zixuan Yi, Sharad Malik, Aarti Gupta, Xujie Si, and Osbert BastaniICML Position Track, 2026, Spotlight
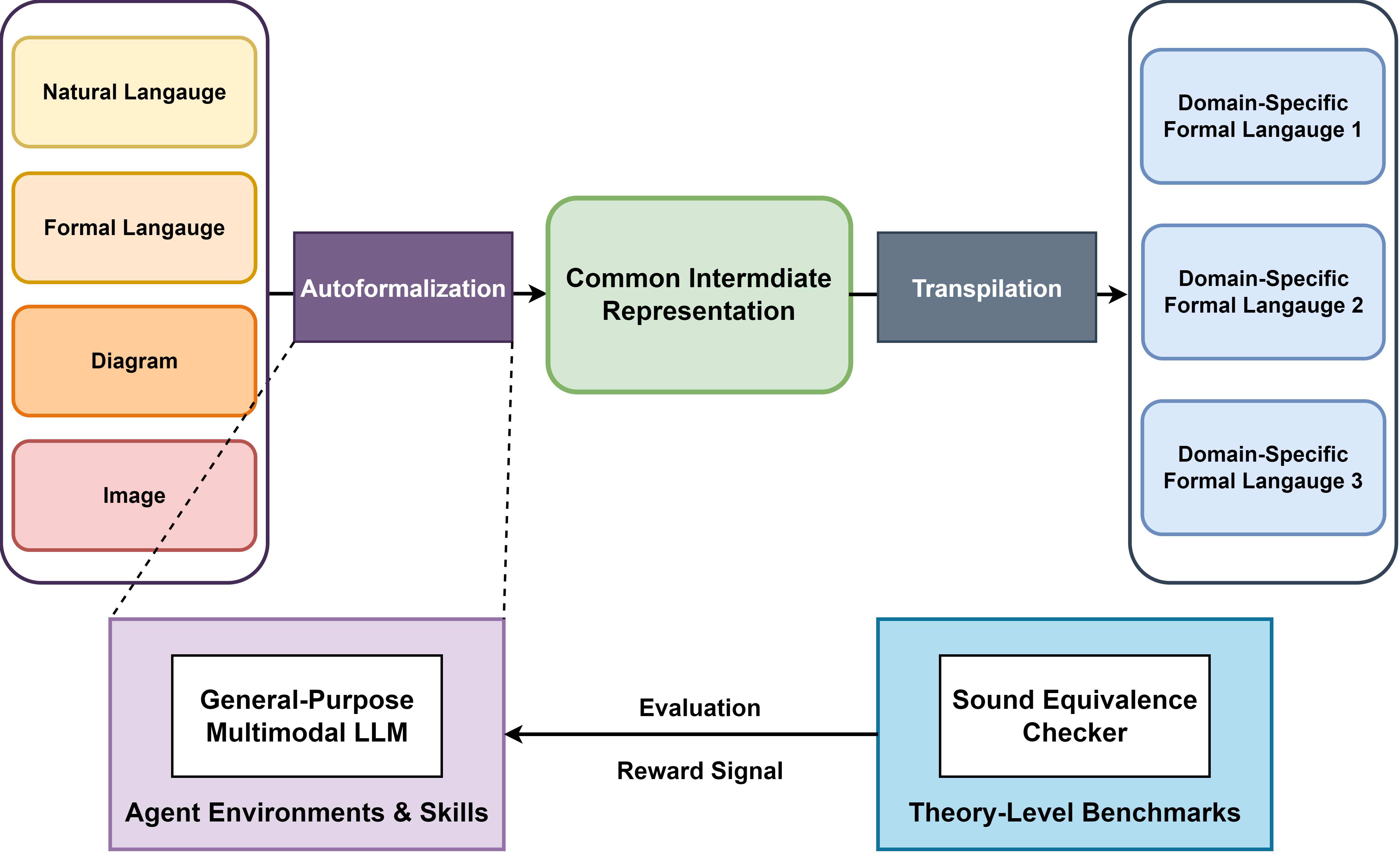
Autoformalization translates informal natural language into formal, machine-verifiable languages. While most work focuses on individual statements, real formalization efforts are inherently theory-level: they require an entire web of axioms, definitions, and lemmas before target theorems can even be stated. In this position paper, we argue for theory-level autoformalization: formalizing complete theories, including all their inter-dependencies, as structured libraries. We examine the significance of this shift, address alternative views, identify open challenges, and propose three promising paths forward.
@article{min2026theory-level, title = {Theory-Level Autoformalization: From Isolated Statements to Unified Formal Knowledge Bases}, author = {Min, Marcus J. and He, Mike and Li, Zhaoyu and Yi, Zixuan and Malik, Sharad and Gupta, Aarti and Si, Xujie and Bastani, Osbert}, journal = {ICML Position Track}, year = {2026}, url = {https://papers.ssrn.com/sol3/papers.cfm?abstract_id=6922158}, } - Marcus J. Min, Yeqi Gao, Wilson Sy, Zhaoyu Li, Xujie Si, and Osbert BastaniICLR, 2026
Existing approaches to autoformalization—the task of translating informal mathematics into formal machine-verifiable languages—rely heavily on pre-defined libraries and expect LLMs to directly generate complete formalizations. These approaches face three fundamental limitations: they are bottlenecked by existing abstractions, they have difficulty handling the complexity of realistic statements, and they do not transfer well across formal languages. We propose Divide and Abstract (DNA), a zero-training framework that addresses these challenges through a two-phase approach. First, DNA extracts common mathematical concepts from the entire corpus and formalizes them as reusable abstractions, extending the target language’s capability. Second, DNA hierarchically decomposes new statements into structured informal clauses, translates each clause using the learned abstractions, and composes them into complete formalizations. Our evaluation on the LeanEuclidPlus and ProofNet-Hard benchmarks demonstrates consistent improvements across multiple model families, achieving up to performance gains over baselines. Notably, DNA enables smaller models to match baselines using much larger models, and shows particularly strong performance on complex mathematical statements requiring nested reasoning. Furthermore, our framework requires no training on target languages, making it effective for low-resource domain-specific languages.
@article{min2026divide, title = {Divide and Abstract: Autoformalization via Decomposition and Abstraction Learning}, author = {Min, Marcus J. and Gao, Yeqi and Sy, Wilson and Li, Zhaoyu and Si, Xujie and Bastani, Osbert}, journal = {ICLR}, year = {2026}, url = {https://openreview.net/forum?id=NjgaeXNit3}, }
2024
- Yangruibo Ding, Jinjun Peng, Marcus J. Min, Gail Kaiser, Junfeng Yang, and Baishakhi RayNeurIPS, 2024
Code Large Language Models (Code LLMs) have excelled at tasks like code completion but often miss deeper semantics such as execution effects and dynamic states. This paper aims to bridge the gap between Code LLMs’ reliance on static text data and the need for semantic understanding for complex tasks like debugging and program repair. We introduce a novel strategy, monologue reasoning, to train Code LLMs to reason comprehensive semantics, encompassing high-level functional descriptions, local execution effects of individual statements, and overall input/output behavior, thereby linking static code text with dynamic execution states. We begin by collecting PyX, a clean Python corpus of fully executable code samples with functional descriptions and test cases. We propose training Code LLMs not only to write code but also to understand code semantics by reasoning about key properties, constraints, and execution behaviors using natural language, mimicking human verbal debugging, i.e., rubber-duck debugging. This approach led to the development of SemCoder, a Code LLM with only 6.7B parameters, which shows competitive performance with GPT-3.5-turbo on code generation and execution reasoning tasks. SemCoder achieves 79.3% on HumanEval (GPT-3.5-turbo: 76.8%), 63.6% on CRUXEval-I (GPT-3.5-turbo: 50.3%), and 63.9% on CRUXEval-O (GPT-3.5-turbo: 59.0%). We also study the effectiveness of SemCoder’s monologue-style execution reasoning compared to concrete scratchpad reasoning, showing that our approach integrates semantics from multiple dimensions more smoothly. Finally, we demonstrate the potential of applying learned semantics to improve Code LLMs’ debugging and self-refining capabilities.
@article{ding2024semcoder, title = {SemCoder: Training Code Language Models with Comprehensive Semantics Reasoning}, author = {Ding, Yangruibo and Peng, Jinjun and Min, Marcus J. and Kaiser, Gail and Yang, Junfeng and Ray, Baishakhi}, journal = {NeurIPS}, year = {2024}, url = {https://arxiv.org/abs/2406.01006}, } - Yangruibo Ding, Marcus J. Min, Gail Kaiser, and Baishakhi RayOOPSLA, 2024
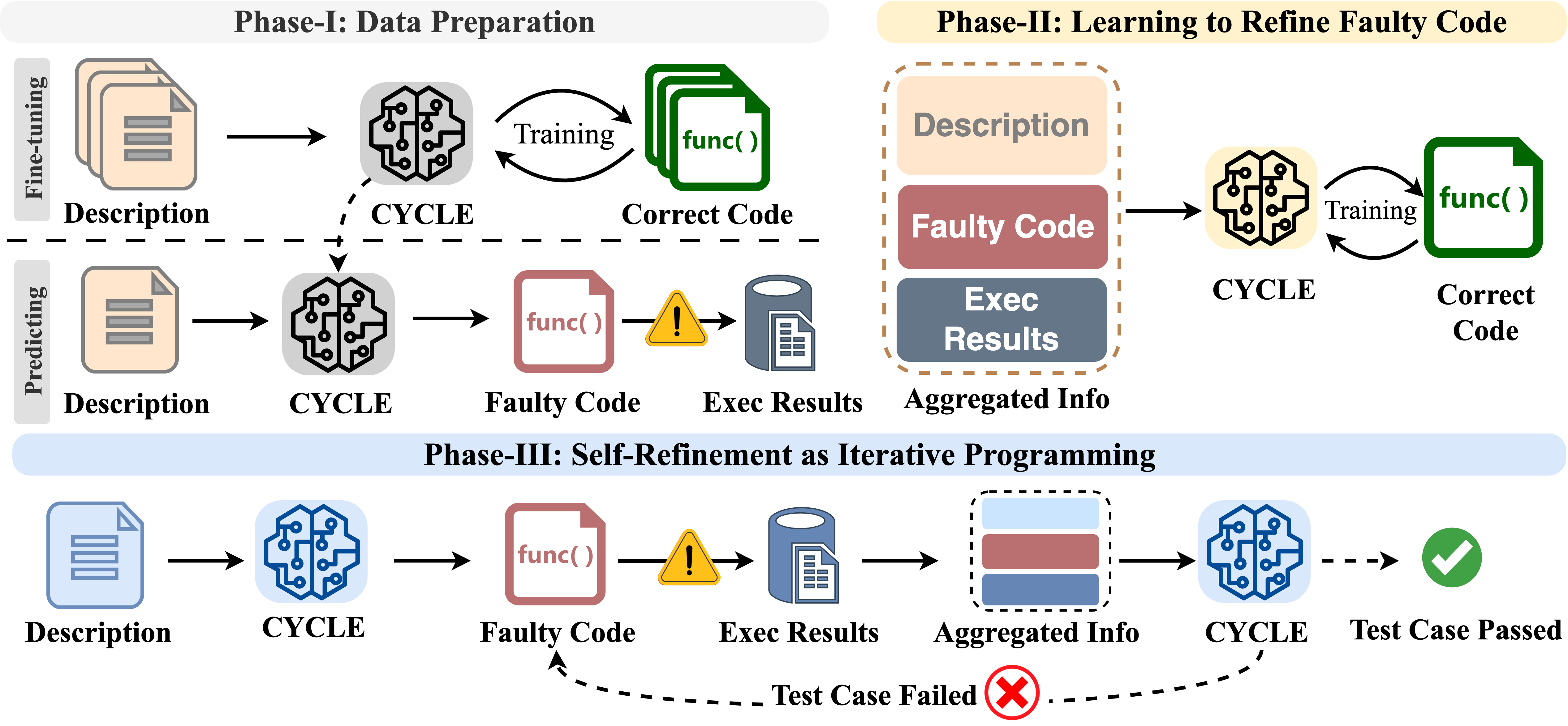
Pre-trained code language models have achieved promising performance in code generation and improved the programming efficiency of human developers. However, their self-refinement capability is typically overlooked by the existing evaluations of code LMs, which focus only on the accuracy of the one-time prediction. For the cases when code LMs fail to implement the correct program, developers actually find it hard to debug and fix the faulty prediction since it is not written by the developers themselves. Unfortunately, our study reveals that code LMs cannot efficiently self-refine their faulty generations as well. In this paper, we propose CYCLE framework, learning to self-refine the faulty generation according to the available feedback, such as the execution results reported by the test suites. We evaluate CYCLE on three popular code generation benchmarks, HumanEval, MBPP, and APPS. The results reveal that CYCLE successfully maintains, sometimes improves, the quality of one-time code generation, while significantly improving the self-refinement capability of code LMs. We implement four variants of CYCLE with varied numbers of parameters across 350M, 1B, 2B, and 3B, and the experiments show that CYCLE consistently boosts the code generation performance, by up to 63.5%, across benchmarks and varied model sizes. We also notice that CYCLE outperforms code LMs that have 3× more parameters in self-refinement.
@article{ding2024cycle, author = {Ding, Yangruibo and Min, Marcus J. and Kaiser, Gail and Ray, Baishakhi}, title = {CYCLE: Learning to Self-Refine the Code Generation}, year = {2024}, journal = {OOPSLA}, url = {https://arxiv.org/abs/2403.18746}, } - Marcus J. Min, Yangruibo Ding, Luca Buratti, Saurabh Pujar, Gail Kaiser, Suman Jana, and Baishakhi RayICLR, 2024
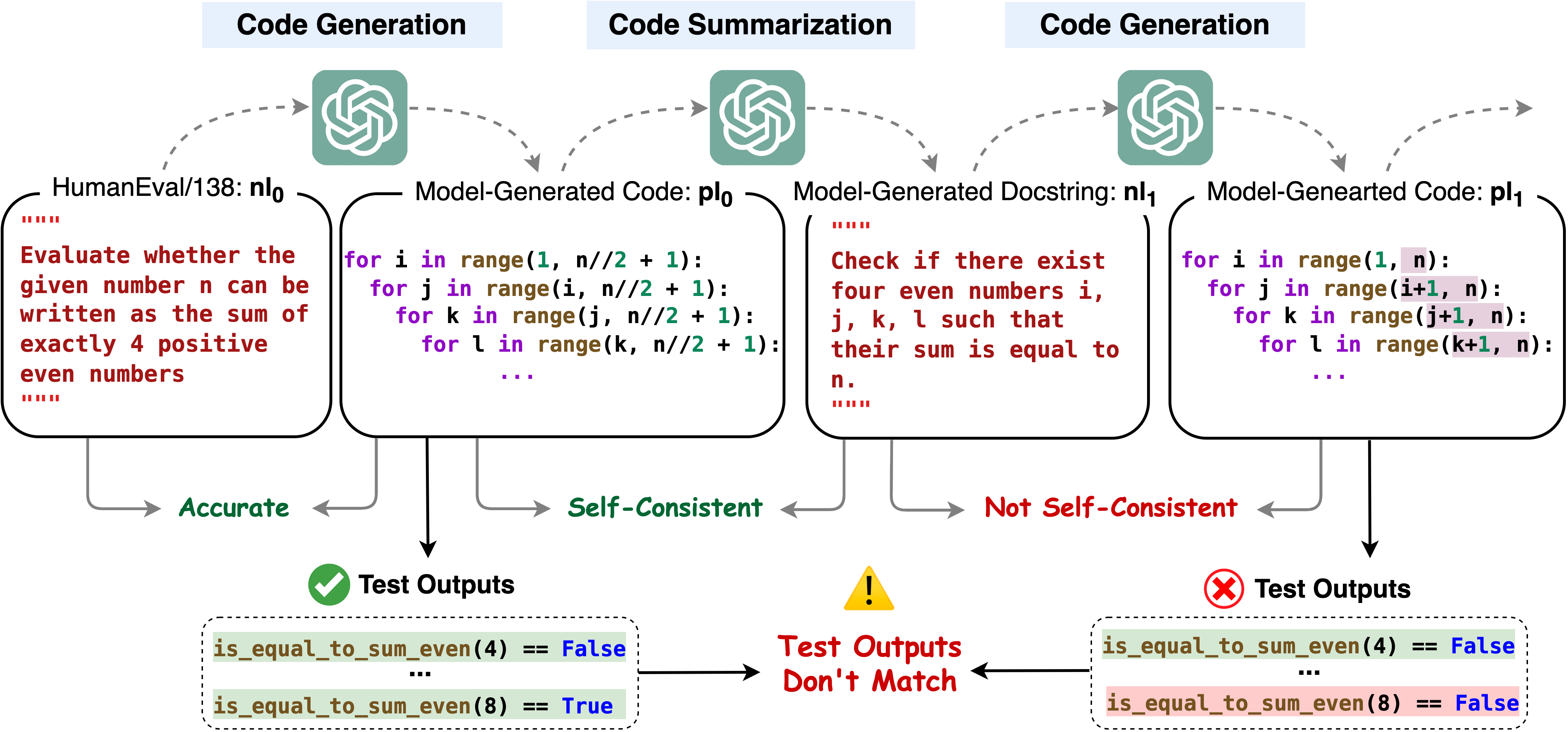
Code Large Language Models (Code LLMs) are being increasingly employed in real-life applications, so evaluating them is critical. While the conventional accuracy evaluates the performance of Code LLMs on a set of individual tasks, their self-consistency across different tasks is overlooked. Intuitively, a trustworthy model should be self-consistent when generating natural language specifications for its own code and generating code for its own specifications. Failure to preserve self-consistency reveals a lack of understanding of the shared semantics underlying natural language and programming language, and therefore undermines the trustworthiness of a model. In this paper, we first formally define the self-consistency of Code LLMs and then design a framework, IdentityChain, which effectively and efficiently evaluates the self-consistency and conventional accuracy of a model at the same time. We study eleven Code LLMs and show that they fail to preserve self-consistency, which is indeed a distinct aspect from conventional accuracy. Furthermore, we show that IdentityChain can be used as a model debugging tool to expose weaknesses of Code LLMs by demonstrating three major weaknesses that we identify in current models using IdentityChain.
@article{min2024beyond, title = {Beyond Accuracy: Evaluating Self-Consistency of Code Large Language Models with IdentityChain}, author = {Min, Marcus J. and Ding, Yangruibo and Buratti, Luca and Pujar, Saurabh and Kaiser, Gail and Jana, Suman and Ray, Baishakhi}, journal = {ICLR}, year = {2024}, url = {https://arxiv.org/abs/2310.14053}, }